-
📝 General Overview
Our team consisted of 2 AI programmers. We decided to split the AI behaviour in two parts. The other AI programmer would focus on making the cars actually drive. Translating the possible inputs for the car to behaviour output. I was responsible for the track registration. How do AI cars know where they are on the track? What direction should they move towards? What is the best driving line?
-
🛞 Take the Wheel!
What prevents a CPU in Mario Kart from brutally crashing Mario into the closest barricade on the track? Do CPUs in Formula 1 know when to overtake the car in front of them? Why do I never feel in a 'hopeless' situation while playing Mario Kart 200cc mirrored Rainbow Road?
🛑 Recommendation: Don't Crash.
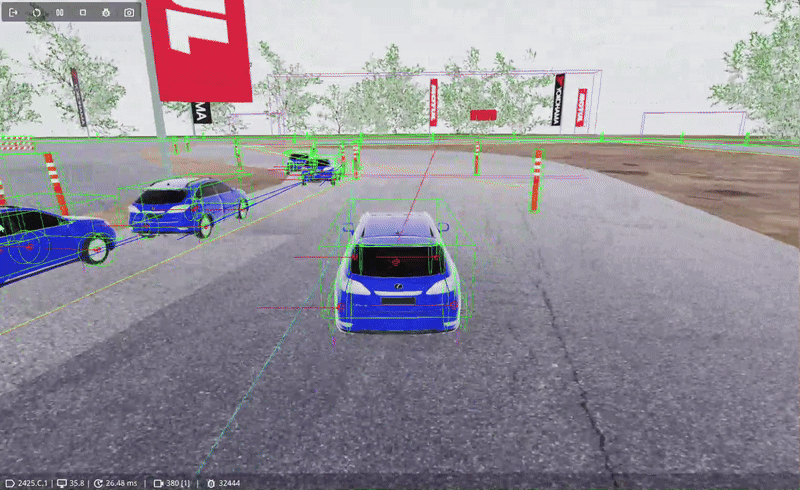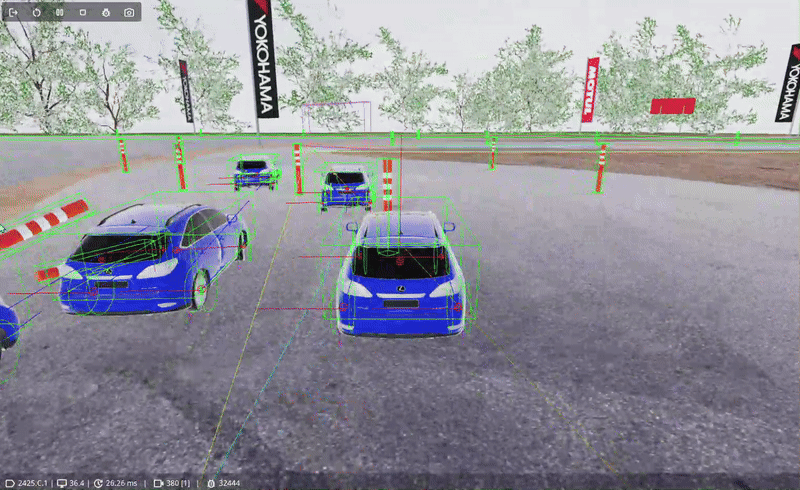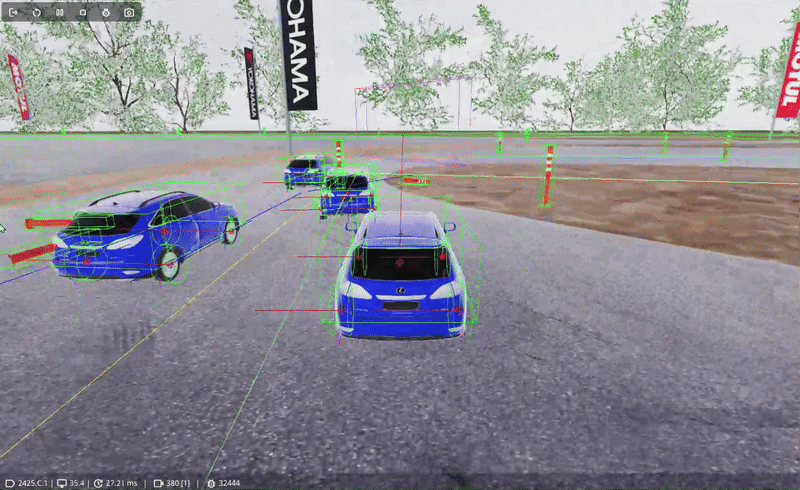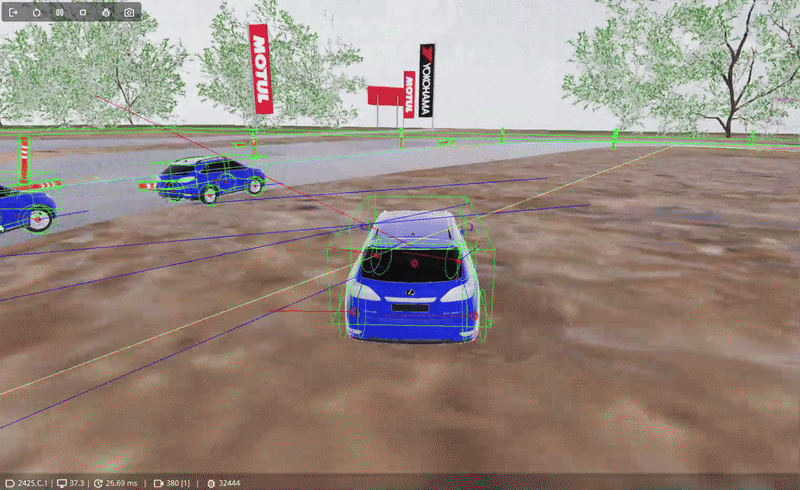
A possible solution, and the one I used, is to use Track Nodes. Track Nodes are simply points placed around the track that contain information about that specific section of the track. They can contain information about the recommended speed to pass through for instance, or the curvature of the track ahead for instance.
Racing agents are able to 'read' the information stored in the next node to determine the best course of action to take. If the agent is driving at 60km/h, and the next node recommends a max speed of 100km/h, the agent can start speeding up. Or if a turn is coming up, the node can recommend a max speed of 50km/h so the agent has time to slow down and take the turn safely.
A basic setup for track nodes in code is the following:

🍌 Banana Peel on the Road.
After creating the track nodes and storing information inside, the question now becomes: How and, more importantly, where do we place them on the tracks?
The answer is that there are multiple possible ways of achieving this; some more involved than others. A possible method is to let someone drive an 'ideal' line, record it, and place track nodes at important decision points. Given our time constraint and the fact we had no way of recording a racing line, we had to opt for an alternative: manually placing it with guesswork. The philosophy for placing nodes was: Space nodes out more on straight roads and add more nodes (and thus more detailed information) in turns. While not optimal, it served our purpose well.
🤖 Steering Away from Predictability.
There's still a problem we need to address that is quite common in pathfinding, namely; the movement looks stiff if the agent just moves from track node to track node. A technique used with A* pathfinding can also be applied here: the Attraction Point.
The attraction point is a location a specified distance in front of the agent on the line of the path it is trying to follow. Instead of directly moving towards the next track node, it moves towards the attraction point, effectively cutting corners in turns.
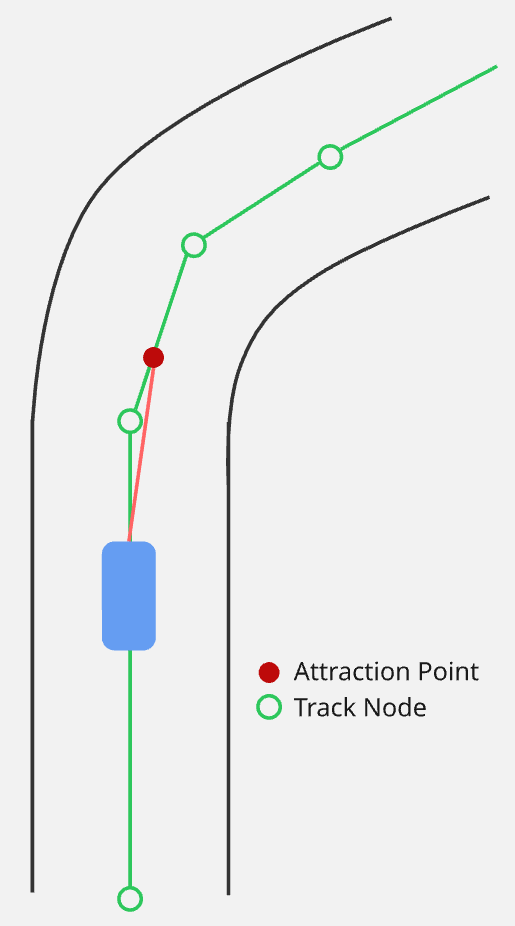
The setup for an attraction point is surprisingly simple, but there are a couple of requirements needed:
1. How far in front of the agent should the attraction point be?
2. How far along the current segment is the agent?
3. Access to all line segments on the track.
That is pretty much it though. Below is a basic code setup with this information.

attractionProgressdetermines position of the attraction point projected on the current line segment.
If theattractionProgressexceeds the current line segment, we are on the next line segment.
Finally, we determine the next position ofattractionPointby lerping betweencurrentSegment.startNodePositionandcurrentSegment.endNodePositionaccording to theattractionProgress.
.png)
The previous implementation does not take into account a situation where the
attractionProgressskips over an entire segment. The above improved version changes the code slightly to smoothly move over each line segment.
To add a bit of variation in the agent's behavior, instead of directly following the attraction point, by introducing a slight perpendicular offset left or right (perpendicular * lateralOffset), the agent moves slightly more organic and with 'errors'.